info@biomedres.us
+1 (502) 904-2126
One Westbrook Corporate Center, Suite 300, Westchester, IL 60154, USA
Site Map

Received: September 03, 2017; Published: September 20, 2017
Corresponding author: Perez Jean Claude, Retired interdisciplinary researcher (IBM), £ 7 avenue de terre-rouge F33127 Martignas Bordeaux metropole France
DOI: 10.26717/BJSTR.2017.01.000374
Fundamental research not yet published enables us to unify, overall, the genomics and proteomics information of any genetic sequence. This fundamental law is based on a bio-mathematics unification of all genetic information (bio-atoms, nucleotides, codons, amino acids, DNA/RNA/Proteins) from the level of the six basic bio-atoms conhsp to the global level of whole genomes. This law, which we name “Universalis Genetic Codes: Global Unified Genetic Codes (GUGC)”, traduces a global genetic tuning and balancing unifying any DNA sequence and its equivalent translated into amino acids. As an indication, one measures a linear Genomics/ Proteomics coupling of 97% for the whole genome of AIDS HIV1- HXB2, length of more than 9000 bp, including about ten genes and enzymes. Concretely, the dynamics of this Genomics/Proteomics coupling is appeared as two correlated curves translating topology and the dynamic evolution of a hierarchical classification of codons throughout the studied sequence. More precisely, the study of these curves shows that this tool highlights the functional areas and active sites within proteins. The specific context of Proteins Self-Assembly area could be an interesting field to run and improve our new basic research approach. Particularly, studying Prions by this method we propose a possible self-interaction with a Genomics/Proteomics correlation coupling ratio of r=99.3%. Such prospects oblige us to propose this new technology in the study of the Genetics of the disease of Alzheimer. We propose results new and not yet published in the three principal tracks of research which are the genes TAU, ApoE4 and BetaA4 Amyloid:
i. In the research way of Professor AVILA (Madrid), we are studying the TAU gene by our technology reveals strong Genomics/Proteomics coupling ratios (r=80%). In other hand, we propose a theoretical Unification of the four splicing variants transcripts of the TAU gene (Epitopes 1, 2, 3 and 4). Then, the common consensus area within TAU is, for all four variants, the first TAU/MAP repeat MOTIF…! One knows that this patterned motif constitutes, very precisely, the “tubulin-binding motif”, constituting a major key element of the functional role of TAU in Alzheimer disease.
ii. We propose also possible interaction simulations-based perspectives involving possible binding/assemblies between the three major alzheimer genes: APP, TAU and Apoe4. These possible interactions (at a theoretical simulation level) correspond to strong couplings genomics/proteomics of the assemblies thus formed. Particularly, we propose a selfassembly with a very higth level coupling (r=94.2%).
Figure 1: Alzheimer betaA4 reverse self-assembly Genomics/Proteomics.
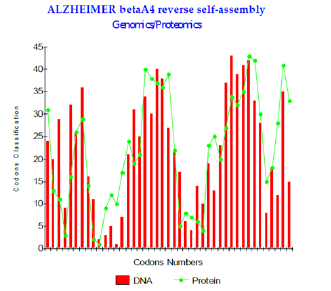
iii. Lastly, concerning the formation of the amyloid plaques, we studied possible self interactions between peptides Beta A4 1-43 and A Beta42: We propose a possible interaction of Amyloid with its self reverse! The Figure 1 below shows this strong link. One measures visually the strong genomis/ proteomis. Coupling correlation of this Amyloids assembly. Moreover, our simulation-based thesis is encouraged by the recent results of Doctor Claudio SOTO (sereno Genova) which bring to us the proof of a symmetrical conformation of Amyloid peptide. There is this symmetry which would allow it “ mirrorlike reverse self-interaction “ that we will suggest. In addition, our results are correlated with the published pathogenicity increases associated with certain mutations of Amyloid peptide Abeta42 (changes A21G, E22Q, E22G and E22K).
a. In a major therapeutic field, the Alzheimer disease, a completely new tool, “GUGC (Global Unified Genetic Code”, being based on new theoretical bases still confidential
b. These global law of Unification Genomics Proteomics, allowed imagining, testing, and simulating a new vision of the role of major genes involved in AD: TAU, APP, ApoE4.
c. Particularly, we could propose and simulate promising new research ways based on self interaction and self-assembly between these genes or peptides, particularly in the microtubule paired helical filaments (TAU) and Amyloid plaques formation (Abeta42). Finally, we introduce a new bioinformatics paradigm dimension to help Alzheimer research field.
Abbreviation: GUGC: Global Unified Genetic Code; Abeta42: Amyloid Plaques Formation
One suspects the APP (Amyloid Precursor Protein) of playing a central part in the disease of Alzheimer. However, this role would not come from the whole gene (long of 770 amino acids), but rather of a small peptide which is detached some by “cleavage” (A-beta1-42), length from 41 to 43 amino acids, it accumulates to form the “ amyloid plaques “, one lends also a neurotoxic role to this small peptide. The therapeutic hopes are multiple: their background is based on a possible blocking of the “complex chains cleavage”, while neutralizing, for example, the enzymes beta-secretase and gamma-secretase, which starts to be identified. Another promising way consist also and especially to understand the causes of the Accumulation and the AGREGATION of these small peptides leading to the formation Of Amyloids Plaques, causes associated with the Disease.
a. In does the study of the APP, our discovery make it possible to highlight certain functions?
b. In particular, does it underline the area of the “cleavage” making emerge small peptide (and perhaps functional causes of this cleavage)? Lastly, that to conclude from the analysis of the small peptide according to this technique?
c. And, especially, as we in addition propose it for Prion, could our simulation tool be able to propose possible scenarios of self-assembly between these small peptides likely to lead to the formation of famous “Plaques Amyloids”?
At the time of the study of gene APP, it appears three types of remarkable results:
a. A bad “ Genomics/Proteomics Coupling “ of Gene App:
Contrary to the majority of the sequences studied up to now, where the genetic agreement reveals linear coefficients of correlation genomics/proteomics always higher than r=0.90 (90%), here, on the contrary, the genetic agreements between genome and proteome of the APP are weak (the maximum obtained is r=0.49). That means, most probably, that this protein is heterogeneous and Not Very stable in its native form.
b. Conditions Of Emergence Of the Small Peptide by “Cleavage”: The small peptide of 41/43 amino acids of sequence: « DAEFRHDSGYEVHHQKLVFFAEDVGSNKGAIIGLMVGGVVIAT »
Is localized towards the end of gene APP (between bases 2013 to 2142, codons 671 to 714). A study focused on this area provides three good reasons which could justify that this small peptide separates, by “cleavage” of the protein precursor APP:
i. This area (towards codons 660 more particularly) appears as very functional as of the analysis of the whole gene APP, length of 770 codons.
ii. Contrary to the other areas of APP, this small area has a very good genomics/proteomics coupling ratio (higher than r=0.9), as of the general study of complete gene APP.
iii. In the neighboring areas of the address of peptide (addresses located upstream and downstream), it very quickly appears very important increasing dissensions and constraints between genomics curve and proteomics curve. These regions of dissensions can be interpreted like areas of potential cleavages.
c. An excellent “ genomics/proteomics coupling “ of the small Peptide:
When small peptide is analyzed alone, it appears, on the contrary, an excellent Agreement Genomics/Proteomics Coupling. One measures a linear correlation “r” higher than 0.8 (80%). Moreover, in this analysis, the amino acids 9/10 would be very functional. We will note that the Biologists observe this peptide under varied lengths. However the pathogenic forms seem to correspond to lengths 43, and 42 more particularly. Let us study coupling Genomics/Proteomics in the case of the peptide of 43 amino acids, often called ” betaA4 1-43” or also ”Abeta 1-43 ”.
Figure 2: Genomics Proteomics Amyloid Abeta 1-43.
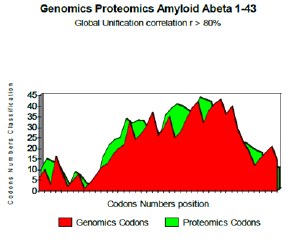
The two curves below show excel it coupling Genomics/ Proteomics, whose linear coefficient of correlation “r” is higher than 0.801. One clearly notices an optimal site towards codon 10 (Figure 2).
Our strategy consisted in seeking possible configurations of interactions peptide-peptide. Such a discovery would constitute a beginning of track towards the understanding of the formation of “Amyloids Plaques“. We validated such a scenario in the interaction between two Prions. Why not also between two Amyloids related to the disease of Alzheimer. Remainder, certain authors note disconcerting analogies between Prion and Amyloid:
i. In both cases, the BETA helix is in the central part of the interaction process then contributes to the Pathogenicity.
ii. Researchers observed an analogy between this BETA area of Peptide Amyloid in its area 15-37 (KLVFFAEDVGSNGAIIGLMVGG) and another region within Prion in 120-142 (KHMAGAAAAGAVVGGLGGYMLGSAM).
Finally, after having imagined and simulated various assumptions of interactions (shifts, role of the active site codon 10 etc). It appeared that one of the scenarios functions too well: It consists in placing in opposite peptide Abeta 1-43 and its turned over homologue “headings “ After research of the Optimal related position there appears that the optimal interaction puts facing Abeta 1-43 and its reverse shifted by one codon, therefore interfering, starting from the second codon.
Figure 3: Alzheimer betaA4 reverse self-assembly of Genomics/Proteomics.
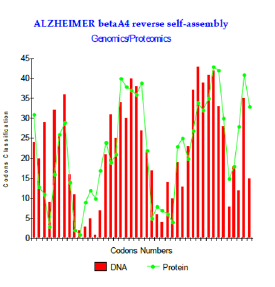
The levels of couplings GENOMICS/PROTEOMICS are very important: the maximum reached is r = 77.5% (Figure 3). The configuration of two put peptides face-to-face discussion is then: Abeta 1-43: DAEFRHDSGY EVHHQKLVFF AEDVGSNKGA IIGLMVGGVV IAT Reverse shift1: TAIVVGGVM LGIIAGKNSG VDEAFFVLKQ HHVEYGSDHR FEA. We even simulated the case, hypothetical, of a possible peptide of 42 amino acids corresponding to codons 2 to 43 and interfering with its reverse returned to a coefficient of linear correlation “r” is about r = 80.6%. Here this example (theoretical) (Figure 4). In fact, this peptide of 42 amino acids is very strongly associated with the experimental pathogenic situations, but it is the Abeta42 referenced peptide, obtained by cleavage of the section of integrating APP codons 1 to 42 included. What does it occur in such a case? And, more particularly, than to say certain changes which were associated with the Pathogenicity of this peptide…?
Figure 4: Genomics Proteomics Amyloid Abeta 42: Reverse Self-interaction Perez-thesis.
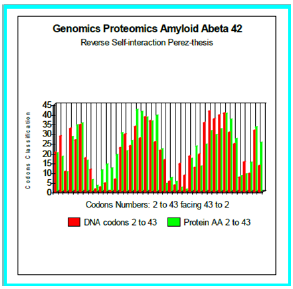
Now, the configuration studied now is thus:
Wild-type: DAEFRHDSGY EVHHQKLVFF AEDVGSNKGA IIGLMVGGVV IA, Reverse: AIVVGGVMLG IIAGKNSGVD EAFFVLKQHH VEYGSDHRFE AD. We simulated six configurations whose certain changes of which it was established than there are Pathogenes (Figure 5). In all do these cases, we test our thesis of “reverse-assembly” Is there a correlation between our simulated forecast and the experiments published?
Figure 5: Coefficient Results of Genomics/Proteomics
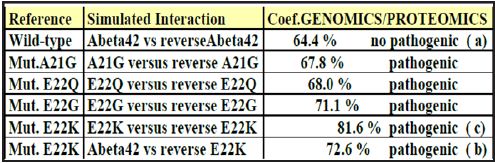
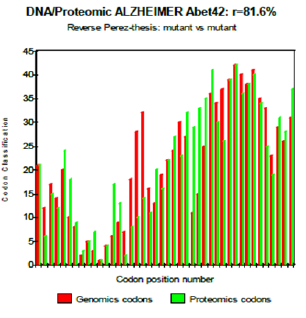
One observes well here how the changes of the amino acids 21 and especially 22 increase coupling GENOMICS/PROTEOMICS of our scenario… knowing that they correspond, THEREFORE, with an increase in PATHOGENITY… We will point out that these two points of significant mutations are just at the median point of peptide (then, also, in the middle of its reverse one!). Effectively: 21=42/2 could one conclude to the “reality” from our thesis? The three curves above correspond to the three noted cases (Figure 6-8) in the preceding table. There are interested more particularly in the case of mutant E22K, there make it possible, by comparison, to locate the causes of this increase in coupling when one passes from the case of interaction between two, wild-types to the hybrid case of interaction of a mutant with a wild-type. Then, finally to the case of interaction of two mutants together. One observes also the attenuation of the peaks of differences Genomics/Proteomics in all first half of the curves (codons 1 to 20: attenuation of the variations green/red) what translates an improvement of the AGREEMENT of Genomics/Proteomics Coupling and, also of the Pathogenicity!
Figure 6: Reverse Perez-thesis: Wild-type case.
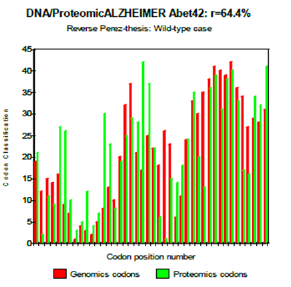
Figure 7: Reverse Perez thesis: Wild-type vs muta.
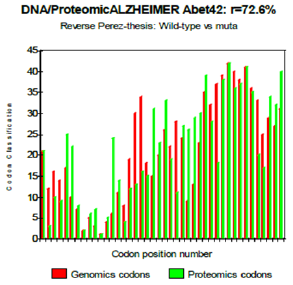
Figure 8: Reverse Perez-thesis: mutant vs mutant.
We here have just shown how:
i. In a major therapeutic field, the Alzheimer disease,
ii. a completely new tool, “GUGC (Global Unified Genetic Code)”, being based on new theoretical bases still confidential.
iii. Those of a law of Unification Proteomics/Genomics.
iv. Allowed to imagine, discover, test and simulate a scenario of “self-assembly” between Amyloids peptides which could explain the formation of “Amyloids Plaques “, central symptom associated with the disease of Alzheimer.
v. Lastly, our thesis is seen reinforced by simulations of case of known mutations points which one knows associated with the Pathogenicity.
All these data illustrate how a new fundamental discovery could very quickly be applied and used by the research world scientific community.
We thank several researchers interested in our approach to the Master Code of Biology Professor Luc Montagnier (Paris), Professor Stanley Prusiner, Professor Diego Rapoport (Buenos Aires), Dr Marco Francisco Paya Torres (MD Alicante), Dr Robert Friedman (MD Santa Fe), Dr François Gros (Pasteur Institute, co-discoverer of RNA messenger with James Watson and Walter Gilbert).


























